Accounting for decisions
A note on decision making for finite beings

The point of this note is to show how decision making can be framed as a kind of counting process. The suggestion is that we can describe a decision between X and Y as being made by counting up and netting out the low-level, detailed pluses and minuses arising in comparing X and Y. Under the perspective presented here, agents consider alternatives on multiple points of comparison (alias aspects), then aggregate the individual comparisons (point-by-point) into an overall comparison of the alternatives. Agents keep accounts in evaluating decision alternatives and choose in light of these records when it is time to decide.
My plan is to make the program of decision accounting plausible by treating examples of decision making in diverse contexts. A common approach that is readily usable will emerge and, I hope, be apparent to the reader. Profuse details of the landscape are ignored in favor of, for the present, seeing a general pattern, one sufficiently promising to beckon subsequent intrepid explorations in detail.
Now to example contexts of decision making.
Imagine we are comparing two spots for today’s lunch, Bob’s and Carol’s, and that we have a certain amount of data for making our decision, shown in the alternatives-outcomes table below. Suppose further that we want to make our decision using only the information in the table.
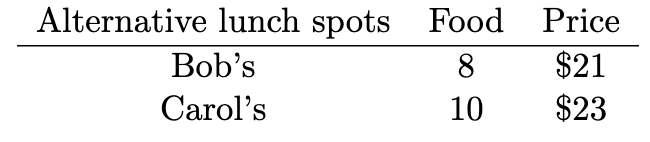
On overall food quality Bob’s gets an 8 (out of 10) and Carol’s gets a full 10. Carol’s is better than Bob’s on the food aspect of the comparison. But we have a second aspect and that is cost. On cost, Bob’s beats Carol’s because it is cheaper.
Neither alternative, Bob’s and Carol’s, is uniformly better across all (both) aspects. How can we decide? There are many methods discussed in the literature on decision making. I want to present here a method that is especially simple and that surprisingly has a broad scope of effective application. The simple method I shall present is a member of a much richer class of similar methods called outranking methods. For the present, this larger class need not detain us. It serves now only to name the kind of approach being presented. Focus on the main point: counting to compare alternatives.
In comparing two alternatives, we seek to determine whether one outranks the other according to the outranking principles to hand. The first step is to determine on an aspect-by-aspect basis if one alternative outranks the other. In doing this, we first specify a threshold of significance for each aspect of comparison. For food we stipulate that a difference of two or more on the scores is significant and on price we say that 3 or more is significant.
The second step is to evaluate each alternative with respect to the other on an aspect-by-aspect basis. Bob’s is significantly worse than Carol’s on food, so Bob’s gets a 0 and Carol’s a 1. On price, the scores are not significantly different according to our prior threshold of acceptance specifications, so each alternative gets a score of 0.5.
The third step is to specify importance weights for the aspects. Keeping things simple, we give food and price equal weights, 0.5 each. The weights serve the purpose of normalization. Final scores will now be between 0 and 1 with higher scores better.
The fourth step is to calculate the weighted averages of the scored alternatives. This yields the following outranking scores table. The mean scores are the outranking scores. For example,
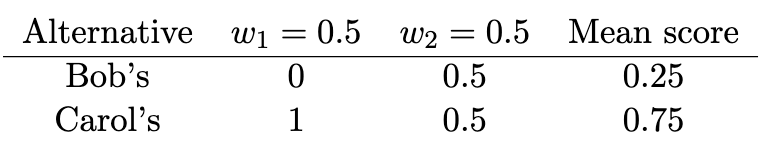
The fifth step in this simplified process is to apply a decision threshold and decide. The idea behind the decision threshold is that an alternative must be sufficiently better if it is to count as outranking another alternative. A decision threshold of 0.6 is commonly used in the outranking literature. Apply it and we find that Carol’s overall outranks Bob’s on this model. In the absence of other considerations we decide to have lunch at Carol’s.
There are any number of caveats, qualifications, refinements, and so on that can apply to this case and similar cases. These issues can, should, and will be explored. Here, however, I want to draw the reader’s attention to two larger issues. The first is the overall pattern present in the outranking method. We compare two alternatives at a time, giving them comparative scores of 1 or 0, or something in between if they are similar. Then we add up the scores for a total comparison. The alternative with the high score provisionally outranks the other and is recommended for choice. Weighting, as already said, is for purposes of normalization and for importing additional information if we have it. This general approach is certainly a heuristic, but a reasonable and practicable one. These are points to be discussed in the sequel.
The second main point to be made is that outranking is a broadly applicable heuristic. To see how and why, we consider two additional decision examples. The presentation is abbreviated in light of the longer discussion of the first example.
In that first example (above) we assumed we knew with (good enough) certainty the scores in the table, viz., the food and price values for the two restaurants. Thus, the first example is said to be one of decision making under certainty. We demonstrated that a basic outranking heuristic procedure could easily and plausibly take us to a good decision.
Our second example is one of decision making under ignorance (alias Knightian uncertainty, strong uncertainty). See the following alternatives-outcomes table.
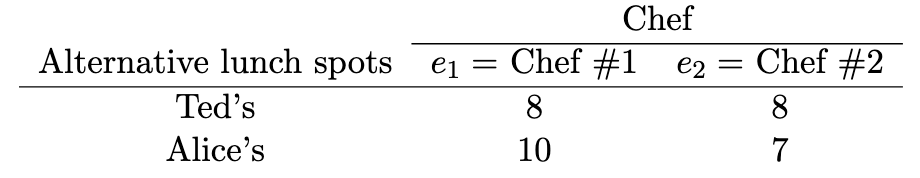
We again deliberate between two lunch spots but now their values to us are determined by which chef is on duty today. Each lunch spot, let us assume, has a first line and a second line chef. Moreover, chef scheduling is coordinated between the two restaurants so that either they both have their chef #1 on duty or both have chef #2 on duty. Perhaps the chefs are spouses and wish to work or be off at the same time. Further assume for the sake of the example that the two restaurants conspire to keep their chef scheduling secret. In consequence, we have no idea whatsoever which chef is on duty. Either event e(1) has occurred and the chef #1 at each restaurant is in charge, or event e(2) has occurred and we have the chef #2s to cook for us. We do not, however, know which event did occur, nor do we have any information about the probability of their occurrences, other than that the two probabilities sum to 1.
How to decide? Apply the simple outranking decision heuristic of the first example, setting the significance levels to 1 for both events (score differences less than or equal to 1 are counted as not significantly different). Again, to get the example going, we specify a decision threshold of 0.6 and set the weights equally. From this we can construct an outranking scores table by the method described above. Here it is.
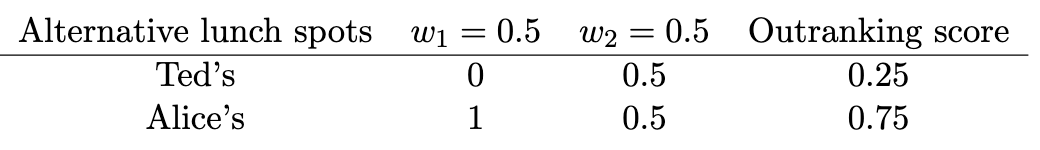
We see in this admittedly concocted example that our basic outranking procedure comes to a reasonable conclusion, but now in a context of ignorance regarding the occurrence of the possible events that drive the outcomes. Two contexts (certainty, ignorance), one decision procedure.
Consider our third example, an abstract case in which we have probabilities. Five events are probable, e(1)–e(5). Each is equally probable at 0.2. The alternatives-outcomes matrix for example 3 follows.
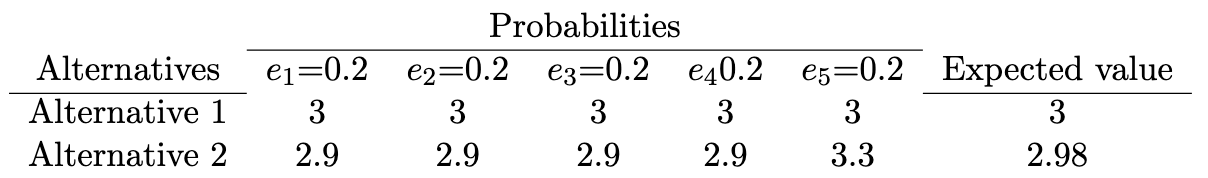
Note that by the expected value decision rule—the standard in standard decision theory—alternative 1 beats alternative 2.
Suppose, however, we have a significance threshold of 0.1 (a difference of 0.1 or less is not counted as significant) and equal weights, then we have this outranking table.

If we as usual stipulate a decision threshold of 0.6, alternative 2 (just barely) outranks alternative 1. Which is the correct recommendation, alternative 1 via expected value or alternative 2 by basic outranking? If the values in the alternatives-outcomes table count as utilities, then we agree that expected value is the correct decision rule. If the values are not denominated as utilities—perhaps they are denominated in dollars or bushels of apples—then expected value has no special claim, other than as a conventional heuristic, and a disputed one at that. What the outranking table demonstrates is that basic outranking has the resources to recommend credibly against naïve use of expected value as a decision rule. To be sure, so does utility theory (Rational Choice Theory). Our heuristic approach loses no power in this comparison and is arguably simpler in concept and easier to use.
Discussion: Heuristic Foundations of Decision Making
Points arising:
This has been a speed drill to demonstrate the potential for outranking as a heuristic decision procedure for the full range of decision contexts: decision making under certainty, under ignorance, and under risk (with known probabilities).1 In short, three contexts, one decision procedure.
Stepping back, the program on offer is one of establishing heuristic foundations for decision making. We find heuristic decision making building blocks and assemble them for application to a growing circle of decision problems. Successful execution of such a program is self-warranting.
A main goal of the program is to develop concepts, tools, and understandings that can be taught to and applied effectively by human beings as the finite beings they are.
A related main goal is to account for and explain animal behavior. Use of heuristics is intended to account for decision making by finite beings, including much of the animal kingdom. The comparisons needed to conduct outranking comparisons are, we believe, often within the capabilities of animals having only a weak number sense and unable to count (much).2
These points should be considered promised but not yet proved. That voyage has only begun. The simple examples in the note are for the purpose of showing the forest and its extent. Detailed examination of the trees—careful application and testing with real world decision cases—is the messy process that must necessarily follow.
There are intermediate cases. These too are amenable to outranking analysis but demonstrating that is beyond the scope of this minimal, very brief introduction.
Deheane, S. (2011). The Number Sense: How the Mind Creates Mathematics (revised and expanded). Oxford University Press, Inc.
Wow Steve, you are a math whiz!!
I may need to read this a few times to even begin to get the gist.
Glad to know where your interests lie.
Big Hug, Elizabeth Johnson