A Note on Robustness
And related concepts

The previous post, “Imperfect Uncertainty,” proposed that decision making in the presence of uncertainty—when relevant probabilities are unavailable or problematic—may often call for decision principles quite distinct from principles used when probabilities are available. The post specifically mentions robustness as a decision principle in the face of uncertainty: When choosing alternatives in the presence of uncertainty, go for alternatives that are comparatively robust. This is a widely received view in the community interested in decision making under uncertainty, whether deep or not.1
A perceptive reader2 asks for more information on robustness. What is it? How can it be characterized with some specificity? These are fair and good questions. They are also questions that require and deserve extended investigations. That has to be postponed. My aim in this Note is:
To present a very high level discussion of the concept of robustness. This should be serviceable for many purposes, at least provisionally.
To present a formal way of representing uncertain choices and formalizing robustness. The claim is not that this exhausts the theory of robustness. Not at all. Instead, the claim is that the formal approach sketched provides insight into robustness, affords extension and generalization of the approach. It is a first step beyond purely informal discussion and it is productive in suggesting new questions and methods.
Characterizing Robustness
The relevant terminology is not at all standardized. I will use “robustness” in the sense I want. Fortunately, this is one of the several commonly agreed senses.
A choice (or a decision or an alternative, etc.) that is robust is one that does comparatively well no matter what happens. It does well come what may. We are uncertain regarding what will happen, so we choose an alternative that will do well, at least comparatively, so no matter what happens.
Robustness can be contrasted with resilience. A choice is said to be resilient if recovery from bad outcomes is comparatively fast and easy. Severe damage may be done, but healing occurs rapidly. One ideally wants robustness and resilience in the face of uncertainty. What else?
We now turn to the problem of measuring robustness quantitatively. Resilience is another matter, but I believe that something similar to the proposed robustness measurement approach can (and should—research!) be done.
Robustness Quantitatively
To begin, we need a formal way of representing (a class of) decision problems under uncertainty. I’m keeping it simple here. Elaborations, refinements, qualifications are for later.
This section can be skipped at first reading
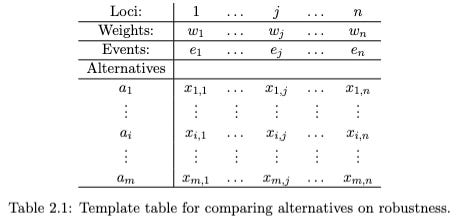
Table 2.1 just below is a template for representing decision making under uncertainty. We are comparing m alternatives, each of which is described as an ordered list (“vector”) of n numerical values.3 These are the x(i,j) values in the table. The position of a value in a vector is significant. Each vector has n loci, 1, ….., n. There are n events or scenarios. These are “things that might happen”. The x(i,j) values are scores for alternative i being chosen and scenario j occurring.
Outranking for robustness
We’ll work by examples now. Suppose we are comparing two alternatives, A and B, and have identified four events or scenarios that we believe to be important for our deliberations. These are e-1, e-2, e-3, and e-4. The payoffs for the two alternatives, given the occurrences of the several scenarios, are given below.
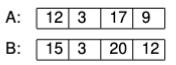
That is, if e-1 occurs and A has been chosen, then the decision maker gets a reward of 12, while if B has been chosen, the reward is 15. Similarly, if e-2 occurs the reward for A is 3 and the reward for B is also 3, etc. We assume higher numbers are better, more preferred and valuable.
Given that we are entirely uncertain which scenario—e-1, …., e-4—will occur, how should we decide between A and B? Well, that turns out to be an easy question in the present case because at every locus, B’s score is equal to or higher than (superior) to A’s score. So, no matter what happens, you do at least as well with B than with A. Therefore choose B. In the jargon, B is said to (weakly) Pareto dominate A. Whenever this happens, it is a safe choice to pick the dominating alternative. This is clearly an example of a decision rule for uncertainty, because it does not rely on knowing any probabilities.
All well and good, but Pareto dominance very often, even usually, fails to obtain. What then? Outranking is a class of ideas, heuristics really, for choosing between alternatives when Pareto dominance is absent.
Now let’s look at a different decision, one that is more typical in not having a Pareto dominant alternative.
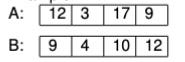
Notice that A is better than B at loci 1 and 3, while B is better than A at loci 2 and 4. We can represent this as follows, giving a 1 or a 0 to the winner or loser at each locus.

We might simply note that the scores in S(A) sum to 2 as do the scores in S(B). So there is a tie. We may or may not be happy with the decision rule that would stop here. What else can we do? Notice that in scenario 2 the scores are nearly tied. A heuristic commonly adopted in outranking analysis is to set an indifference threshold. We might for any or all of the loci set an indifference threshold of, say 1 or 2. Then if at a locus the two values are within the indifference threshold we judge that the actual difference is not enough to make a real difference and we assign each alternative a score of 1/2. In the present case this leads to:
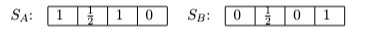
Now we have to incorporate the weights. We do so minimally for the sake of the example, setting them equally, each to 0.25 (=1/n). We net out the score for each alternative as the weighted average of its scores.
Now, A has a higher net score than B and is above the conventional level of 0.6. Therefore we are going to say that A outranks B under the present outranking measure. The intuitive idea to be captured is that A outranks B if, when aggregating their locus-by-locus comparison scores, A scores higher than B. This is meant to capture a notion of “On balance, A is better than B, given the scenarios under consideration.”
What does this have to do with robustness? A lot. I urge that if we can agree on an outranking measure, such as that described here, then ceteris paribus the alternative that outranks the others is presumably more robust. I propose outranking as a quantitative operationalization of robustness.
Points arising:
This outranking procedure, like all outranking procedures, is a heuristic. It can certainly go wrong. The question is instead, do we have something better? I claim that outranking (here and more generally) is prima facie an acceptable heuristic for robustness, absent other heuristics that are upon reflection better. Further, I also claim that there are rarely better alternative measures of robustness than a well-constructed outranking procedure. This is something to be investigated, however.
There are in fact many outranking procedures that have been proposed. The one developed above is only meant for illustration of concepts. For introduction to this body of work see Greco, S., Ehrgott, M., & Figueira, J. R. (Eds.). (2016). Multiple Criteria Decision Making: State of the Art Surveys (2nd ed.). Springer. Finding a small group of outranking procedures most suitable for determinations of robustness (and then resilience) is today an important research challenge.
The proposal here—to use outranking for assessing robustness in decision making under uncertainty—is innovative in proposing an MCDM (multi-criteria decision making) method for this purpose. See related work: Clark, R., & Kimbrough, S. O. (2024). Representing Knightian Uncertainty in Agent-Based Models. Computational Social Science of the Americas 2024, Santa Fe, NM and Wang, K., Staudt, P., & Kimbrough, S. O. (2025). Analytic MCDM: Heuristics on the Pareto Frontier. Proceedings of the 2025 International Conference of The Computational Social Science Society of the Americas. Computational Social Science 2025, Santa Fe, NM. To be investigated: Whether, as I suspect, outranking is an especially advantageous MCDM method for judging robustness (and resilience) or whether other methods can serve as well or better.
With formalization comes commitment to a focus. This is easily seen in the examples just discussed. We modeled four scenarios. How should decision makers proceed when they are aware that their models may be incomplete and that they may learn more complete versions, depending on upcoming events? This question spawns a plethora of vexing questions like it. Literature is emerging, although it seems largely unconnected with active practice. Example: Steele, K., & Stefánsson, H. O. (2021). Beyond Uncertainty: Reasoning with Unknown Possibilities. Elements in Decision Theory and Philosophy. https://doi.org/10.1017/9781108582230 and references therein.
The emerging picture on robustness is that it is a complex, multi-faceted concept, which can be tested and explored using outranking MCDM methods (among others). What are better formalizations? What are better measurement methods?
Including the DMDU community, decision making under deep uncertainty, among others. https://www.deepuncertainty.org/ See for a good introduction: Water Utility Climate Alliance. (2019). Decision-Making Under Deep Uncertainty (DMDU). U.S. Climate Resilience Toolkit. https://toolkit.climate.gov/course-lessons/decision-making-under-deep-uncertainty-dmdu.
Thanks to Eric K. Clemons.
Importantly for scope of application, the numerical values may be cardinal or ordinal values, and these may be mixed (some loci cardinal, others ordinal) under the outranking proposal developed here.